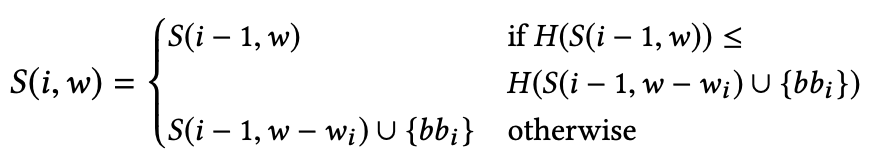原文
Log20基本思路:可以通过静态分析确定基本块,给定输出日志序列的规模限制(可根据需求调整),目标是最小化日志语句放置的熵,通过动态规划求解这个最优化问题
- 确定程序的基本块组成,以及这些基本块的所有可能的执行路径
- 规定每个基本块能且只能放置一条LPS
- 基于执行路径以及被观测到的出现概率计算所有基本块的被执行期望,作为基本块的权重
- 在给定基本块的权重之和限制下,选择LPS的放置策略S,使得放置S的熵最小
方法概述
日志位置的信息量——消除执行路径歧义
- 信息量最大:每个唯一的路径输出一个唯一的日志序列。
信息量较低:多个唯一路径输出相同的唯一日志序列的位置。 - 每个唯一的日志序列都可以由多个唯一的路径打印出来。
形式化定义
- 一个程序由一组基本块(bb)组成,记为BB= {bb1, bb2, …, bbn}
- 执行路径 Pi=[bb1, …, bbk] 定义为 基本块 的序列
- 程序是所有可能执行路径的集合EP={P1, …, Pm}
- 放置S是程序BB中放置了唯一的LPS的基本块构成的子集,即S ⊆ BB,每个基本块中只能放置唯一一个LPS
- 在放置S下,执行路径Pi输出日志序列Li,所有可能的日志序列的集合O(S)= {L1, …, Lk}
- 日志序列Li=[l1, …, lm]的可能路径集PP(Li)= {Pi , …, Pj}:执行时输出Li的路径集,是EP的子集
- 消歧路径DP(S)= {PP(L) | L ∈ O(S)}:所有可能路径集的集合
- 放置S诱导了对所有可能执行路径的集合EP的一个划分,即消歧路径DP(S) (划分为多个可能路径集PP(L))
- 推论:对于任何PP1, PP2 ∈ DP(S)、PP1 ∩ PP2 = ∅ 且 所有PP ∈ DP(S)的并集为EP
放置S的路径消除歧义能力
- 定义不同放置之间的路径消除歧义能力大小为一个偏序关系 S1 ⪰ S2 iff DP(S1) 是 DP(S2) 的完善,即对于每个PP∈DP(S1),存在PP′∈DP(S2) s.t. PP ⊆ PP′
- 这意味着S1比S2更能消除歧义
对于任何执行路径Pi输出的日志序列 Li∈O(S1) 和 Li’∈O(S2),PP(Li)⊆PP(Li’),其中Li和Li’是两个放置S1和S2下执行路径Pi的输出; - 这反过来又意味着开发人员有更少的可能执行路径来消除歧义。
- 这意味着S1比S2更能消除歧义
- 若 S1 ⪰ S2 且 DP(S1) != DP(S2),则 S1 ≻ S2。
- S ∪ S′ ⪰ S,即在放置S中添加更多LPS,将导致更明确的位置。
- 反之不成立,S ⪰ S′ ̸⇒ S ⊇ S′,即放置S比S′具有更强的消除歧义能力,并不一定意味着S是S′的超集。
放置S的熵
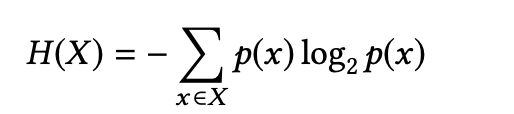
- p(x) 代表观察执行路径x被观测到的概率;X来表示程序的所有可能的执行路径。
p(x)=执行路径x的出现次数/生产系统中采样的路径总数 - 从直觉上讲,具有熵值H的程序意味着程序员在事后分析期间有2^H的可能执行路径来消除歧义。
- 可能路径数量较少的程序具有较低的熵,因此不确定性较低。
- 对于路径数量相同的程序,路径越可预测,熵就越低。
- 熵为0的程序意味着没有不确定性,即只有一条路径。
- 放置S的熵:
- 计算放置S的某个日志L的熵HL(X)
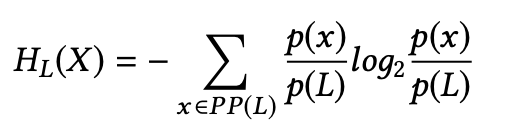
其中,p(L)是程序中日志L的路径的概率,p(x)/p(L)是日志L的可能路径集PP(L)中所有可能的路径中选择路径x的概率 - 使用所有可能的日志L∈O(S)计算放置S的熵HS(X)
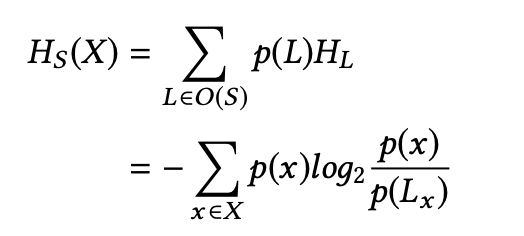
其中,Lx是在放置S下执行路径产生的日志
- 计算放置S的某个日志L的熵HL(X)
- 由此,可以计算不同放置S的熵来比较他们之间的信息量大小,即便他们之间不满足偏序关系 S1 ⪰ S2
- 定理:如果 S ⪰ S ′,那么HS ≤ HS′,无论路径的概率分布如何(即更能消除歧义的放置的熵更小)
LPS放置算法
- 算法输入
- 运行时执行路径及其频率
- 系统的Java字节码(用于确定每个基本块中记录变量值的效果,并识别请求的开始和结束)
- slowdown阈值
- 算法目标:在给定slowdown阈值目标下,确定将LPS放置在哪里、要包含哪些变量值,并最小化开销限制
- 计算基本块权重w并排序
- 对于每个基本块,权重w=其被遍历(执行)的期望次数
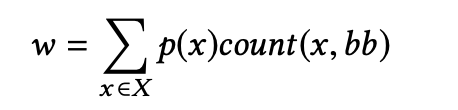
- 权重越高的基本块被执行得越频繁,在其中放置日志语句的开销越大
- 将所有基本块{bb1, bb2, …, bbn}按权重从小到大排序,使得wi ≤ wi+1
- 动态规划状态定义:给定一组基本块(BB),每个基本块有一个权重(wi),目标是找到一个放置S⊆BB,使得:
- 放置S中所有基本块的权重之和w不超过阈值WT
- 熵HS最小化
- 状态转移方程:根据当前基本块是否能在增加权重的同时显著减少熵来决定是否纳入日志放置方案